Introduction
This vignette demonstrates a complex, real-world application of ABC to infer key epidemiological parameters from early outbreak data. Specifically, we aim to estimate the basic reproduction number (R0) and the generation time distribution using only linked case data that includes symptom onset times and observation delays.
During the early stages of an outbreak, detailed information like who infected whom (a “transmission tree”) is often incomplete or unknown. However, if we can observe some linked transmission pairs (e.g., through contact tracing), we can use the times between symptom onsets in these pairs—the serial interval—to learn about the underlying generation time (the time between infection in a primary case and infection in a secondary case).
This is a challenging inference problem because: 1. Infection
times are hidden: We only observe symptom onset and reporting
times, which are delayed and stochastic. 2. Observation is
biased: Cases are only observed if their symptom onset and
reporting happen within the observation window. This “right-censoring”
distorts the observed distributions. 3. Parameters are
linked: R0 is mathematically related to the growth rate
(r0) and the generation time distribution via the
Wallinga-Lipsitch equation.
tidyabc provides a flexible framework to build a
simulation model that captures this complexity and then use ABC to infer
the hidden parameters.
Simulation
tidyabc includes a synthetic dataset generated from a
branching process model which we are using for this example
(sim_outbreak) which is supposed to replicate the early
days of an infectious disease outbreak where very little is known about
the pathogen and its epidemiological parameters.
sim_params = sim_outbreak$parameters
observed = sim_outbreak$contact_tracing
R0_truth = sprintf("%1.1f", sim_params$R0)
r0_truth = sprintf("%1.2f", sim_params$r0)
gt_truth = sprintf("%1.1f \u00B1 %1.1f", sim_params$mean_gt, sim_params$sd_gt)
onset_truth = sprintf("%1.1f \u00B1 %1.1f", sim_params$mean_onset, sim_params$sd_onset)
obs_truth = sprintf("%1.1f \u00B1 %1.1f", sim_params$mean_obs, sim_params$sd_obs)- Branching Process:
The core outbreak is simulated as a stochastic branching process with
a constant R0 of 2.0 and with a gamma distributed
generation time with mean and SD of 4.0 ± 2.0, together these imply an
initial growth rate of 0.19.
After infection a proportion of people experience symptoms with a random delay with mean and SD of 7.0 ± 5.0. Of those with symptoms a proportion are detected with a random delay with mean and SD of 5.0 ± 3.0. The outbreak is simulated to day 40, after which point no further cases can be observed.
The Observed Data
From this simulated outbreak, we extract three key pieces of
information to use as our observational data (obsdata) for
ABC:
- Primary Case Onset Times:
ggplot(observed, aes(x=onset_time))+geom_histogram(binwidth = 1)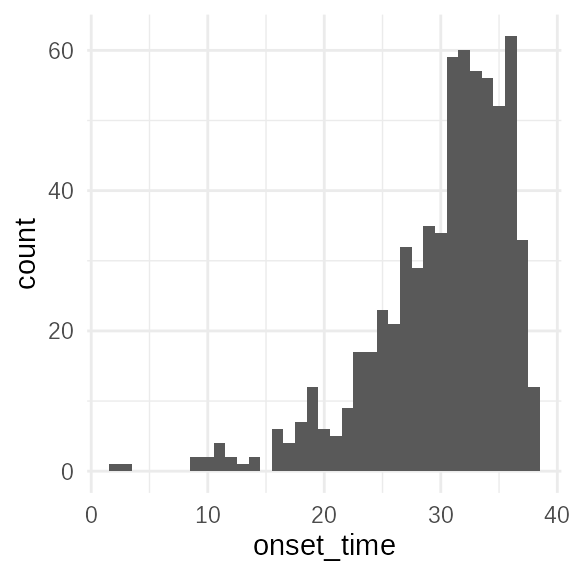
This histogram shows the distribution of symptom onset times for all observed primary cases. The shape is influenced by the exponential growth rate of the outbreak, the symptom onset delay distribution, and the delay to observation.
Delay to observation
# Data
delay_distribution = observed %>% dplyr::transmute(
obs_delay = obs_time - onset_time
)
ggplot(delay_distribution, aes(x = obs_delay))+geom_histogram(binwidth = 1)+
xlab("symptom to observation")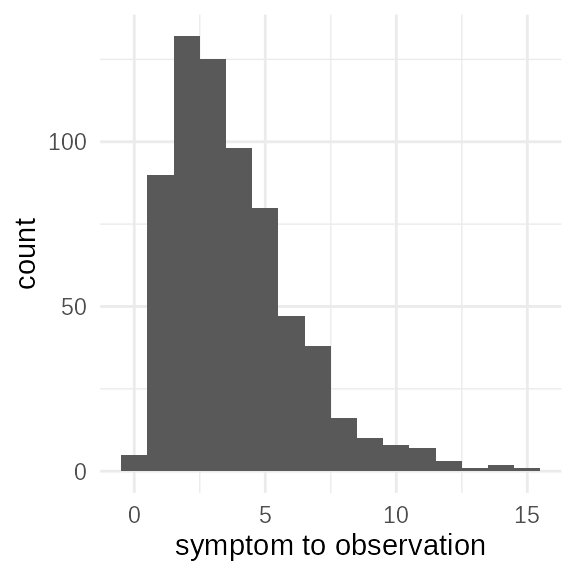
This shows the distribution of delays between symptom onset and when
the case was observed. This reflects the mean_obs and
sd_obs parameters. In an exponentially growing outbreak
longer delays to observation may be be fully represented due to right
censoring.
Observed serial interval
serial_pairs = observed %>%
inner_join(
observed,
by = c("id" = "contact_id"),
suffix = c(".1", ".2")
) %>%
transmute(
serial_interval = onset_time.2 - onset_time.1 #order known
# serial_interval = abs(onset_time.2 - onset_time.1) #order uncertain
)
ggplot(serial_pairs) +
geom_histogram(aes(x = serial_interval), binwidth = 1)+
xlab("symptom serial interval (given observed)")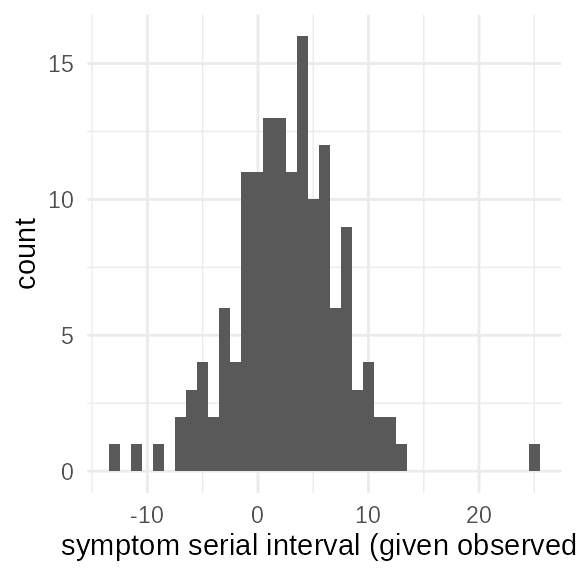
This is the most critical piece of data. The serial interval is the time between symptom onsets in observed transmission pairs. Because symptom onset is itself delayed from infection, the serial interval is a noisy and potentially biased proxy for the true generation time. Our model must account for this relationship. Longer serial intervals are not as frequently observed in the context of exponential growth as long intervals between cases are less likely to have been observed yet.
obsdata = list(
onset = as.numeric(observed$onset_time),
diff = as.numeric(delay_distribution$obs_delay),
si = as.numeric(serial_pairs$serial_interval)
)The Inference Model
Our goal is to fit a model that can simultaneously explain all three observed data components. The model makes explicit assumptions about the hidden processes:
Model Assumptions
- Transmission Dynamics: Infection times follow a process of constant exponential growth with rate \(r_0\).
-
Delays:
- Time from infection to symptom onset is Gamma-distributed (\(\mu_{onset}\), \(\sigma_{onset}\)).
- Time from symptom onset to observation is Gamma-distributed (\(\mu_{obs}\), \(\sigma_{obs}\)).
- The true generation time (time between infections in a pair) is Gamma-distributed (\(\mu_{gt}\), \(\sigma_{gt}\)).
\[ \begin{align} t_{max} - T_{inf} &\sim Exp(r_0) \\ \Delta T_{inf \rightarrow onset} &\sim Gamma(\mu_{onset},\sigma_{onset}) \\ \Delta T_{onset \rightarrow obs} &\sim Gamma(\mu_{obs},\sigma_{obs}) \\ \Delta T_{gt} &\sim Gamma(\mu_{gt},\sigma_{gt}) \\ \end{align} \]
Secondary cases are generated from primary cases with a poisson process with rate equal to the reproduction number \(R_0\) and the time of infection of secondary cases (\(T_{inf_2}\)) by the generation time.:
\[ \begin{align} T_{onset} &= T_{inf} + \Delta T_{inf \rightarrow onset} \\ T_{obs} &= T_{onset} + \Delta T_{onset \rightarrow obs}\\ N_{inf_1 \rightarrow inf_2} &\sim Poisson(R_0) \\ T_{inf_2} &= T_{inf_1} + \Delta T_{gt} \\ \Delta T_{onset_1 \rightarrow onset_2} &= \Delta T_{gt} + \Delta T_{inf_2 \rightarrow onset_2} - \Delta T_{inf_1 \rightarrow onset_1} \\ \end{align} \]
- Observation Process: A primary case is only “observed” if its symptom onset is after day 0 and its observation time is before \(T_{obs}\). A secondary case is only observed if the primary case was observed and its symptom onset is after day 0 and its observation time is also before \(T_{obs}\).
\[ \begin{align} O_1 &= I(t_0 \le T_{onset_1}, T_{obs_1} \le t_{max}) \\ O_{1,2} &= I(O_1, t_0 \le T_{onset_2}, T_{obs_2} \le t_{max})\\ T_{onset_1}|O_1 &\Rightarrow \text{primary case times}\\ \Delta T_{onset_1 \rightarrow obs_1}|O_1 &\Rightarrow \text{onset to interview delay}\\ \Delta T_{onset_1 \rightarrow onset_2}|O_{1,2} &\Rightarrow \text{onset to onset serial interval}\\ \end{align} \]
-
Parameter Linkage: The basic reproduction number
R0 is not a free parameter. It is determined by
r0and the generation time distribution through the Wallinga-Lipsitch formula, specific for gamma distributed generation times:
\[ \begin{align} R_0 = (1 + \frac{r_0\sigma_{gt}^2}{\mu_{gt}})^{\frac{\mu_{gt}^2}{\sigma_{gt}^2}} \end{align} \]
The Simulation Function (sim1_fn)
The mathematical formulation of the model is implemented below,
showing how the hidden infection times (T_inf) are used to
generate the observed symptom times (T_onset), observation
times (T_obs), and serial intervals (derived from linked
pairs).
This function is fully self contained and using
carrier::crate to bind the observation window
T_obs and the number of primary cases n from
the observed data.
n = nrow(observed)
sim1_fn = carrier::crate(
function(r0, mean_onset, sd_onset, mean_obs, sd_obs, mean_gt, sd_gt, R0, ...) {
# Primary case infection time
# exponentially distributed in time. Need to make sure we have enough samples
# before t0 observation cutoff to account for early observed cases.
t_early = - stats::qgamma(0.99,mean_onset,sd_onset) # t starts at 0
t_inf_1 = tidyabc::rexpgrowth(n, r0, T_obs, t_early)
onset_delay = tidyabc::rgamma2(n, mean_onset, sd_onset)
obs_delay = tidyabc::rgamma2(n, mean_obs, sd_obs)
t_onset_1 = t_inf_1 + onset_delay
t_obs_1 = t_onset_1 + obs_delay
# Primary case observations:
# Onset after t0 and observed before T
obs_1 = t_obs_1 < T_obs & t_onset_1 > 0
t_inf_1 = t_inf_1[obs_1]
t_onset_1 = t_onset_1[obs_1]
t_obs_1 = t_obs_1[obs_1]
n1 = length(t_inf_1)
# Secondary case. Numbers of secondary cases are poission(R0). Could add
# dispersion here and fit it also
# Only observed primary will be observed secondary so we can restrict to
# observed subset
# browser()
case_2ary = stats::rpois(n1,R0)
index_1ary = rep(seq_along(case_2ary), case_2ary)
n2 = length(index_1ary)
gt_delay = tidyabc::rgamma2(n2, mean_gt, sd_gt)
onset_delay_2 = tidyabc::rgamma2(n2, mean_onset, sd_onset)
obs_delay_2 = tidyabc::rgamma2(n2, mean_obs, sd_obs)
t_inf_2 = t_inf_1[index_1ary] + gt_delay
t_onset_2 = t_inf_2 + onset_delay_2
t_obs_2 = t_onset_2 + obs_delay_2
# order dependent
serial_interval = floor(t_onset_2) - floor(t_onset_1[index_1ary])
# order independent
# serial_interval = abs(floor(t_onset_2) - floor(t_onset_1[index_1ary]))
# Secondary case observations
obs_2 = t_obs_2 < T_obs & t_onset_2 > 0
serial_interval = serial_interval[obs_2]
t_onset_2 = t_onset_2[obs_2]
return(list(
onset = floor(t_onset_1),
diff = floor(t_obs_1) - floor(t_onset_1),
si = serial_interval
))
},
T_obs = sim_params$T_obs,
n=n
)It performs the following steps:
-
Simulate Primary Infections: Generates
nprimary infection times from an exponentially growing process, starting early enough to account for long symptom delays. - Add Delays for Primary Cases: Adds symptom onset and observation delays, then applies the observation filter.
-
Simulate Secondary Infections: For each observed
primary case, it generates a Poisson(
R0) number of secondary cases. - Add Delays for Secondary Cases: Adds their own generation time delay, symptom onset delay, and observation delay.
-
Calculate Observed Quantities: Computes the final
vectors for
onset,diff(observation delay), andsi(serial interval) from the simulated and filtered data.
The Scoring Function (scorer1_fn)
The scorer function compares the simulated output to the observed data using the Wasserstein distance, which is well-suited for comparing distributions of event times. It also uses the mean absolute difference between simulated and observed data, to give some more information about the most important aspect of the serial interval distribution.
scorer1_fn = function(simdata, obsdata) {
onset = calculate_wasserstein(simdata$onset, obsdata$onset)
diff = calculate_wasserstein(simdata$diff, obsdata$diff)
si = calculate_wasserstein(simdata$si, obsdata$si)
mad_si = abs(mean(simdata$si) - mean(obsdata$si))
return(list(
sim_onset = onset,
sim_diff = diff,
sim_si=si,
sim_mad_si = mad_si
))
}It returns a list of four components: - sim_onset,
sim_diff, sim_si: Wasserstein distances for
the three main data components. - sim_mad_si: The absolute
difference in the mean serial interval. This provides
an additional, direct constraint on the central tendency of the serial
interval, complementing the distributional comparison from the
Wasserstein distance.
We test the sim_fn and scorer_fn pair to
ensure they work correctly with the observed data.
test = tidyabc::test_simulation(
sim_fn = sim1_fn,
scorer_fn = scorer1_fn,
params = sim_params,
obsdata = obsdata
# debug=TRUE
)
# .gg_hist(test$obsdata$onset)Inference with ABC
We now perform ABC to infer the true parameters from the
obsdata.
Priors
We specify priors for the model parameters. The priors for the gamma
distribution hyper-parameters (mean_*, sd_*)
are constrained to be “convex” (mean > sd), ensuring the
distributions have a single mode, which is a reasonable assumption for
biological delays. The prior for r0 is set to allow for
growth rates consistent with the observation window. The R0
parameter is not given a prior; it is a deterministic
function of r0, mean_gt, and
sd_gt.
priors = priors(
r0 ~ unif(-0.1, 0.7),
mean_onset ~ unif(0, 12),
sd_onset ~ unif(0, 8),
mean_obs ~ unif(0, 12),
sd_obs ~ unif(0, 8),
mean_gt ~ unif(0, 12),
sd_gt ~ unif(0, 8),
R0 ~ (1+r0*sd_gt^2/mean_gt) ^ (mean_gt^2 / sd_gt^2),
~ is.finite(R0) & R0 > 0 & R0 < 12,
~ mean_onset > sd_onset,
~ mean_obs > sd_obs,
~ mean_gt > sd_gt
)
priors## Parameters:
## * r0: unif(min = -0.1, max = 0.7)
## * mean_onset: unif(min = 0, max = 12)
## * sd_onset: unif(min = 0, max = 8)
## * mean_obs: unif(min = 0, max = 12)
## * sd_obs: unif(min = 0, max = 8)
## * mean_gt: unif(min = 0, max = 12)
## * sd_gt: unif(min = 0, max = 8)
## Constraints:
## * is.finite(R0) & R0 > 0 & R0 < 12
## * mean_onset > sd_onset
## * mean_obs > sd_obs
## * mean_gt > sd_gt
## Derived values:
## * R0 = (1 + r0 * sd_gt^2/mean_gt)^(mean_gt^2/sd_gt^2)ABC Workflow
We run a multi-stage ABC workflow:
-
Initial Rejection Sampling
(
abc_rejection):
- We perform a quick, low-resolution rejection fit with
n_sims=1000andacceptance_rate=0.5. - The primary goal is not to get the final answer,
but to analyze the resulting component scores using
posterior_distance_metrics(). This helps us calibrate thescoreweightsto ensure the serial interval (sim_si,sim_mad_si) has a strong influence on the distance calculation, as it is the most informative data for inferring the generation time and R0.
abc_fit = abc_rejection(
obsdata = obsdata,
priors_list = priors,
sim_fn = sim1_fn,
scorer_fn = scorer1_fn,
n_sims = 1000,
acceptance_rate = 0.5,
parallel = TRUE
)## ABC rejection, 1 wave.
# summary(abc_fit)
metrics = posterior_distance_metrics(abc_fit)
# make the serial interval fitting much more important:
scoreweights1 = metrics$scoreweights -
Sequential Monte Carlo (
abc_smc):
- Using the calibrated
scoreweights, we run a more efficient SMC fit withn_sims=8000. - SMC iteratively refines the proposal distribution, allowing it to home in on the high-posterior-density region more effectively than rejection sampling.
smc_fit = abc_smc(
obsdata = obsdata,
priors_list = priors,
sim_fn = sim1_fn,
scorer_fn = scorer1_fn,
n_sims = 8000,
acceptance_rate = 0.25,
#debug_errors = TRUE,
parallel = TRUE,
scoreweights = scoreweights1
)## ABC-SMC## SMC waves: ■ 1% | wave 1 ETA: 5m## SMC waves: ■■ 2% | wave 2 ETA: 5m## SMC waves: ■■ 3% | wave 3 ETA: 5m## SMC waves: ■■ 4% | wave 4 ETA: 5m## SMC waves: ■■ 5% | wave 5 ETA: 5m## SMC waves: ■■■ 6% | wave 6 ETA: 5m## SMC waves: ■■■ 7% | wave 7 ETA: 5m## SMC waves: ■■■ 8% | wave 8 ETA: 5m## SMC waves: ■■■■ 9% | wave 9 ETA: 5m## SMC waves: ■■■■ 10% | wave 10 ETA: 5m## SMC waves: ■■■■ 11% | wave 11 ETA: 4m## SMC waves: ■■■■■ 13% | wave 12 ETA: 4m## SMC waves: ■■■■■ 14% | wave 13 ETA: 4m## SMC waves: ■■■■■ 15% | wave 14 ETA: 4m## SMC waves: ■■■■■■ 16% | wave 15 ETA: 4m## SMC waves: ■■■■■■ 17% | wave 16 ETA: 4m## SMC waves: ■■■■■■ 18% | wave 17 ETA: 4m## SMC waves: ■■■■■■■ 19% | wave 18 ETA: 4m## SMC waves: ■■■■■■■ 20% | wave 19 ETA: 4m## SMC waves: ■■■■■■■ 21% | wave 20 ETA: 4m## SMC waves: ■■■■■■■■ 22% | wave 21 ETA: 4m## SMC waves: ■■■■■■■■ 24% | wave 22 ETA: 4m## SMC waves: ■■■■■■■■ 25% | wave 23 ETA: 4m## SMC waves: ■■■■■■■■■ 26% | wave 24 ETA: 4m## SMC waves: ■■■■■■■■■ 27% | wave 25 ETA: 4m## SMC waves: ■■■■■■■■■ 28% | wave 26 ETA: 4m## Converged on wave: 27
summary(smc_fit)## ABC SMC fit: 27 waves - (converged)
## Parameter estimates:
## # A tibble: 8 × 4
## # Groups: param [8]
## param mean_sd median_95_CrI ESS
## <chr> <chr> <chr> <dbl>
## 1 R0 1.921 ± 0.178 1.904 [1.587 — 2.289] 1989.
## 2 mean_gt 4.648 ± 0.952 4.571 [2.709 — 7.368] 1989.
## 3 mean_obs 5.188 ± 0.433 5.158 [4.216 — 6.619] 1989.
## 4 mean_onset 5.711 ± 1.144 5.671 [3.058 — 8.874] 1989.
## 5 r0 0.173 ± 0.012 0.172 [0.142 — 0.208] 1989.
## 6 sd_gt 3.550 ± 1.442 3.578 [0.616 — 6.792] 1989.
## 7 sd_obs 3.277 ± 0.461 3.236 [2.300 — 4.779] 1989.
## 8 sd_onset 4.286 ± 1.004 4.196 [2.172 — 7.020] 1989.This is generally quite slow for the relative large number of waves and simulations it requires until convergence. It has good matching between the estimated parameters and the truth for initial growth rate, reproduction number and observation delays. It is uninformed about delay to onset (and this is inherent in the model and data), and the generation time is somewhat constrained and the mode aligns with the true value but the median is still somewhat high.
plot(smc_fit,truth = sim_params)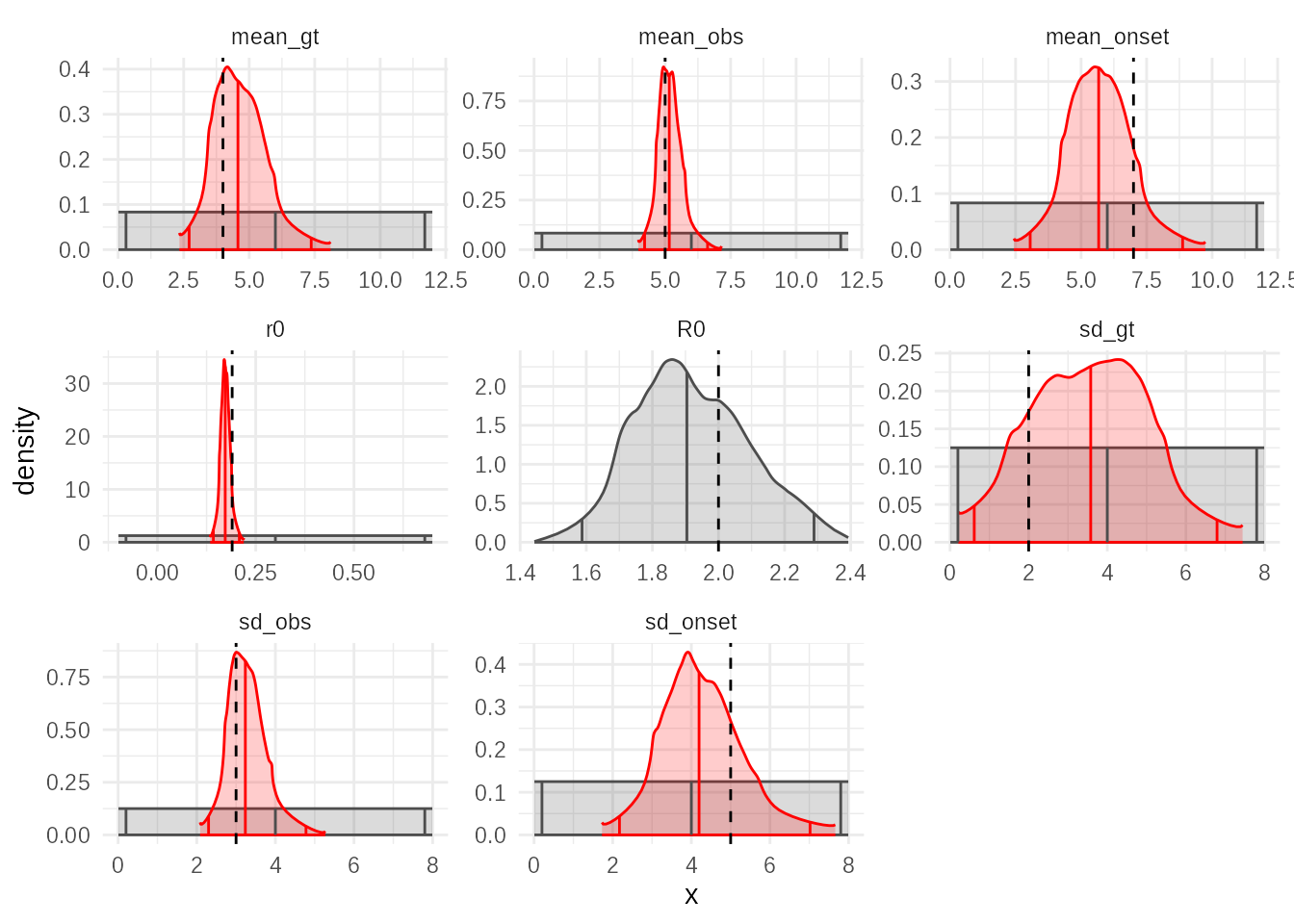
plot_evolution(smc_fit,truth = sim_params)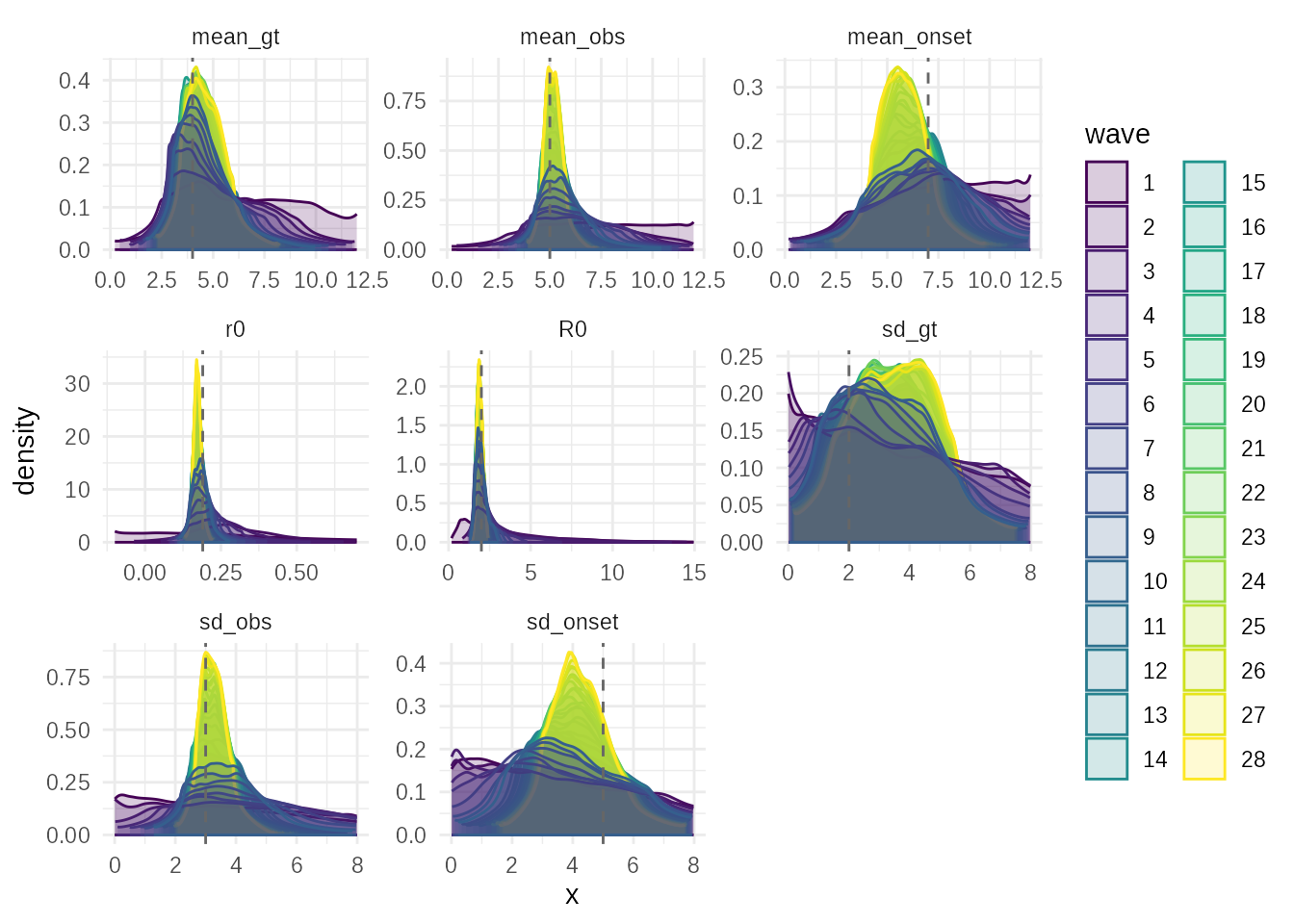
-
Adaptive ABC (
abc_adaptive):
- Finally, we run the Adaptive ABC algorithm. This method fits empirical distributions to the posterior from each wave to create the next proposal, which can be very effective for complex, non-Gaussian posteriors.
- We use
widen_by = 1.2to provide a safety net against particle degeneracy.
adaptive_fit = abc_adaptive(
obsdata = obsdata,
priors_list = priors,
sim_fn = sim1_fn,
scorer_fn = scorer1_fn,
n_sims = 4000,
acceptance_rate = 0.2,
# debug_errors = TRUE,
parallel = TRUE,
scoreweights = scoreweights1,
widen_by = 1.2
)## ABC-Adaptive## Adaptive waves: ■ 0% | wave 1 ETA: 6m## Adaptive waves: ■ 1% | wave 3 ETA: 5m## Adaptive waves: ■■ 2% | wave 6 ETA: 5m## Adaptive waves: ■■ 3% | wave 8 ETA: 5m## Adaptive waves: ■■ 4% | wave 10 ETA: 5m## Adaptive waves: ■■■ 5% | wave 12 ETA: 5m## Adaptive waves: ■■■ 6% | wave 14 ETA: 5m## Adaptive waves: ■■■ 7% | wave 16 ETA: 5m## Adaptive waves: ■■■ 8% | wave 18 ETA: 5m## Adaptive waves: ■■■■ 9% | wave 20 ETA: 5m## Adaptive waves: ■■■■ 10% | wave 22 ETA: 5m## Adaptive waves: ■■■■ 11% | wave 24 ETA: 4m## Adaptive waves: ■■■■■ 12% | wave 26 ETA: 4m## Adaptive waves: ■■■■■ 14% | wave 28 ETA: 4m## Adaptive waves: ■■■■■ 14% | wave 29 ETA: 4m## Adaptive waves: ■■■■■■ 15% | wave 31 ETA: 4m## Adaptive waves: ■■■■■■ 17% | wave 33 ETA: 4m## Adaptive waves: ■■■■■■ 17% | wave 34 ETA: 4m## Converged on wave: 36## Adaptive waves: ■■■■■■ 18% | wave 35 ETA: 4m
summary(adaptive_fit)## ABC adaptive fit: 36 waves - (converged)
## Parameter estimates:
## # A tibble: 8 × 4
## # Groups: param [8]
## param mean_sd median_95_CrI ESS
## <chr> <chr> <chr> <dbl>
## 1 R0 1.878 ± 0.201 1.853 [1.637 — 2.242] 711.
## 2 mean_gt 4.009 ± 0.723 3.784 [2.470 — 7.962] 711.
## 3 mean_obs 4.987 ± 0.254 4.925 [4.377 — 6.492] 711.
## 4 mean_onset 6.563 ± 1.044 6.276 [3.433 — 10.363] 711.
## 5 r0 0.181 ± 0.011 0.182 [0.133 — 0.215] 711.
## 6 sd_gt 2.630 ± 1.075 2.629 [0.436 — 5.929] 711.
## 7 sd_obs 2.958 ± 0.331 2.937 [2.430 — 4.723] 711.
## 8 sd_onset 4.812 ± 1.176 4.914 [2.146 — 7.439] 711.The adaptive algorithm is quicker, less focussed on exploration and more on convergence. With the settings above it can identify the growth rate, reproduction number, generation time mean, observation delay mean and SD to a high degree of accuracy. In this case it tends to generate distributions that are very peaked but with heavy tails, leading to wide 95% credible intervals even when the central estimate seems very close. The model is not informative about the onset distribution and this affects its predictive ability for the generation time SD.
plot(adaptive_fit,truth = sim_params)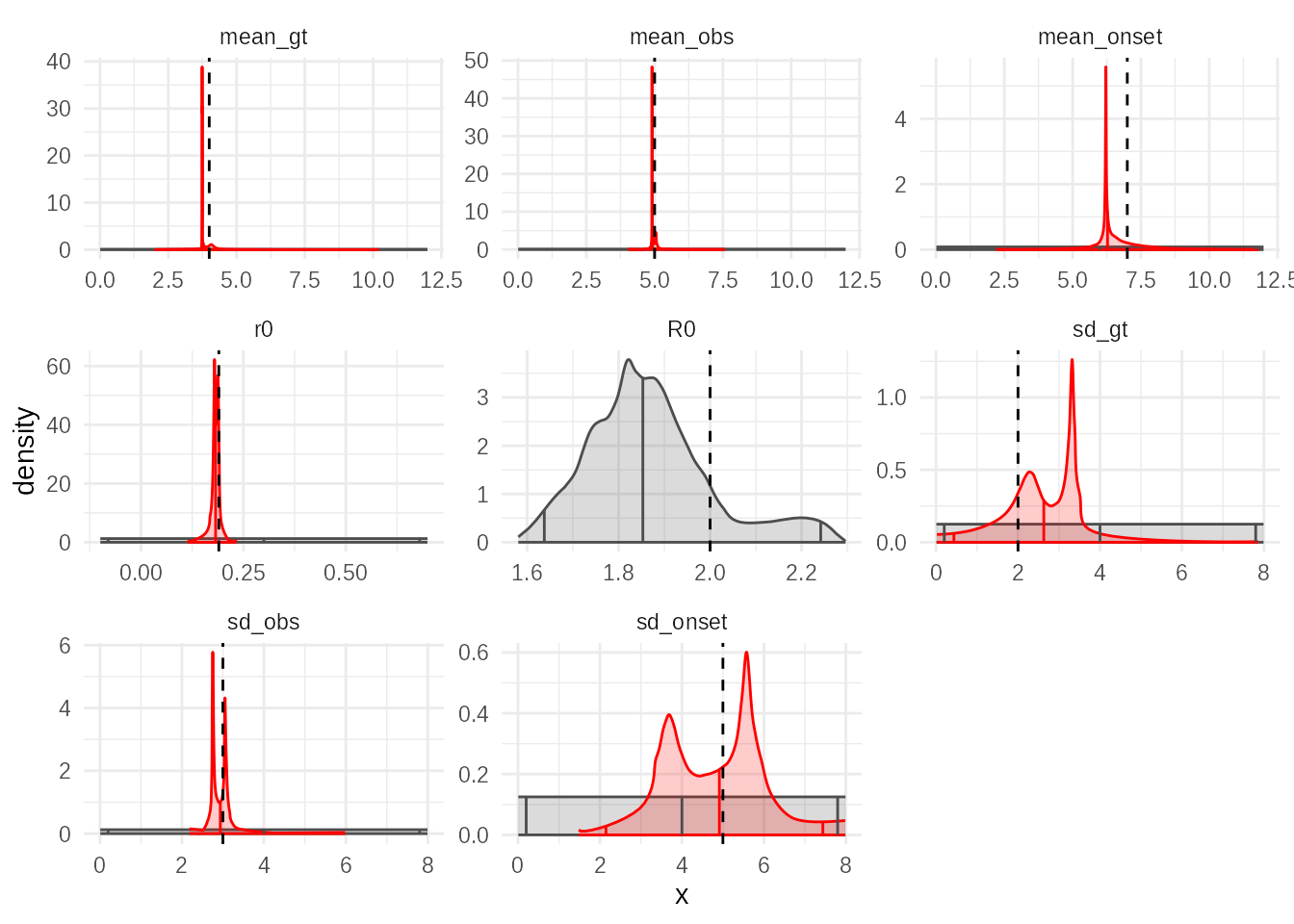
The evolution plot shows how the posterior for each parameter evolved over the adaptive waves, demonstrating the algorithm’s convergence.
plot_evolution(adaptive_fit,truth = sim_params)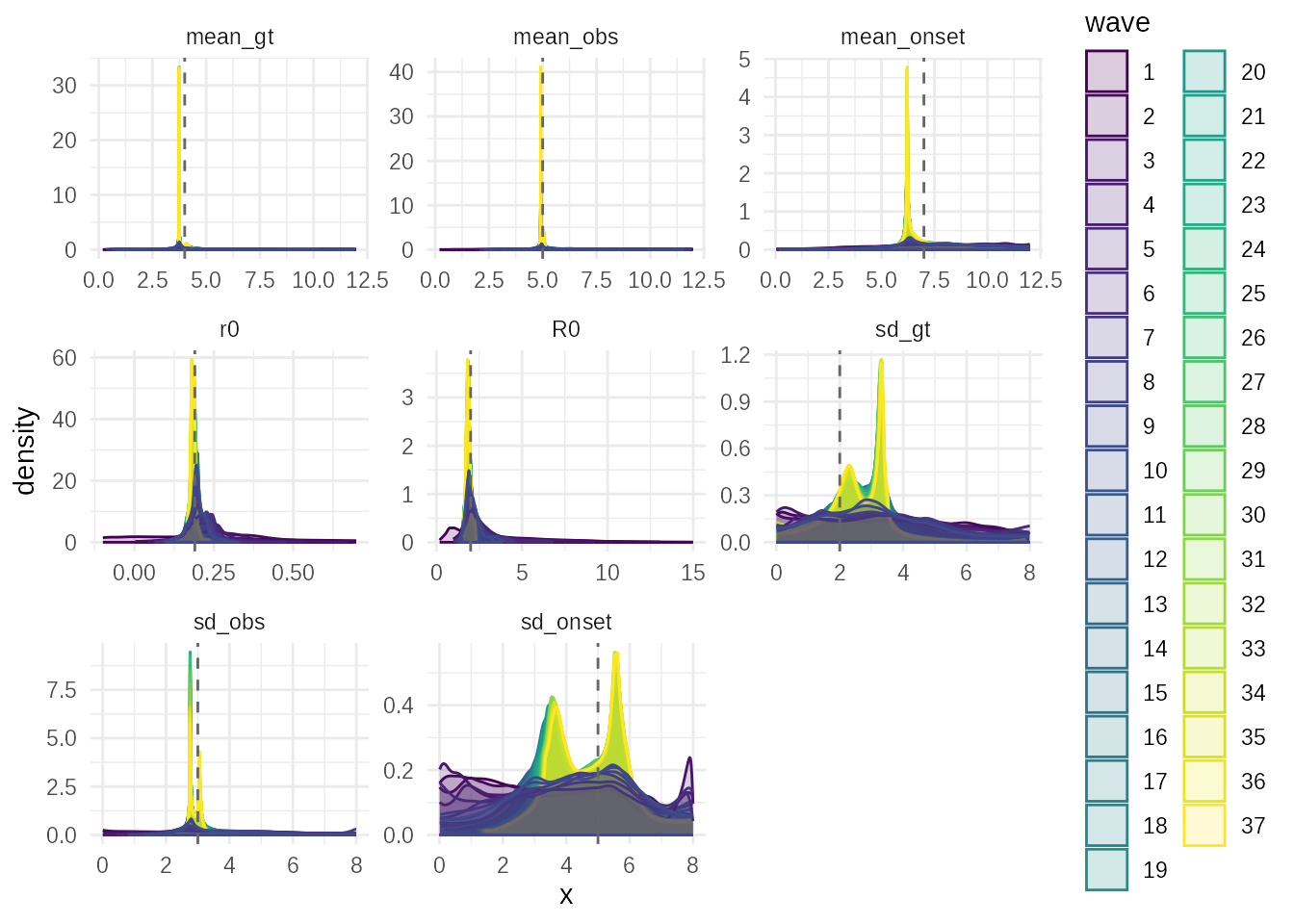
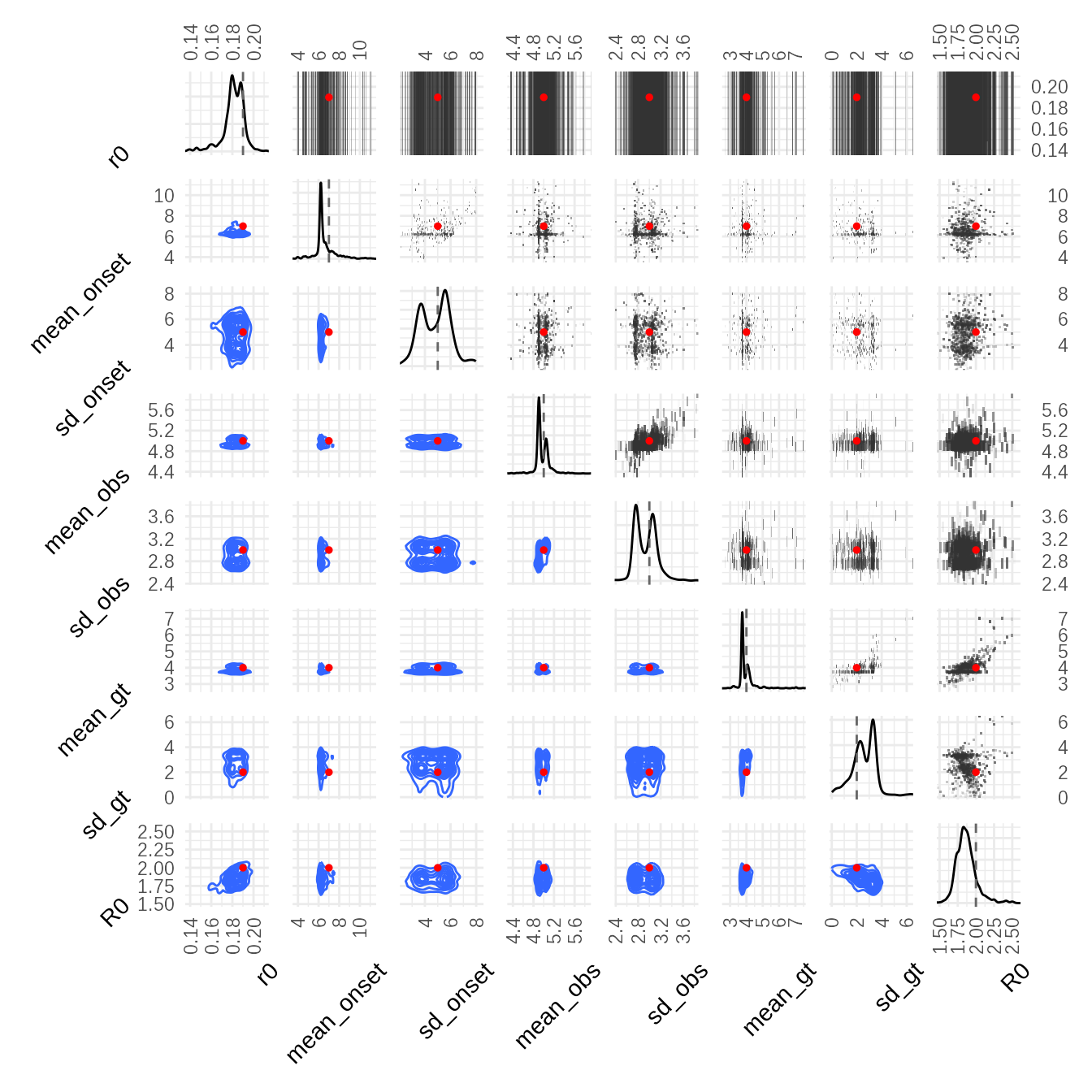
A correlation plot accounting for weighting reveals correlations
between parameters in the final posterior (e.g., r0 and
mean_gt are often correlated).
plot_correlations(adaptive_fit,truth = sim_params) & ggplot2::theme(
axis.title.y = ggplot2::element_text(angle=45,vjust=0, hjust=1),
axis.title.x = ggplot2::element_text(angle=45, hjust=1) #,vjust=1, hjust=0.5)
)
-
plot_convergence(adaptive_fit): The key diagnostic for iterative methods, showing the decline in distance (abs_distance), increase in ESS, and stabilization of parameter estimates (rel_mean_change).
plot_convergence(adaptive_fit)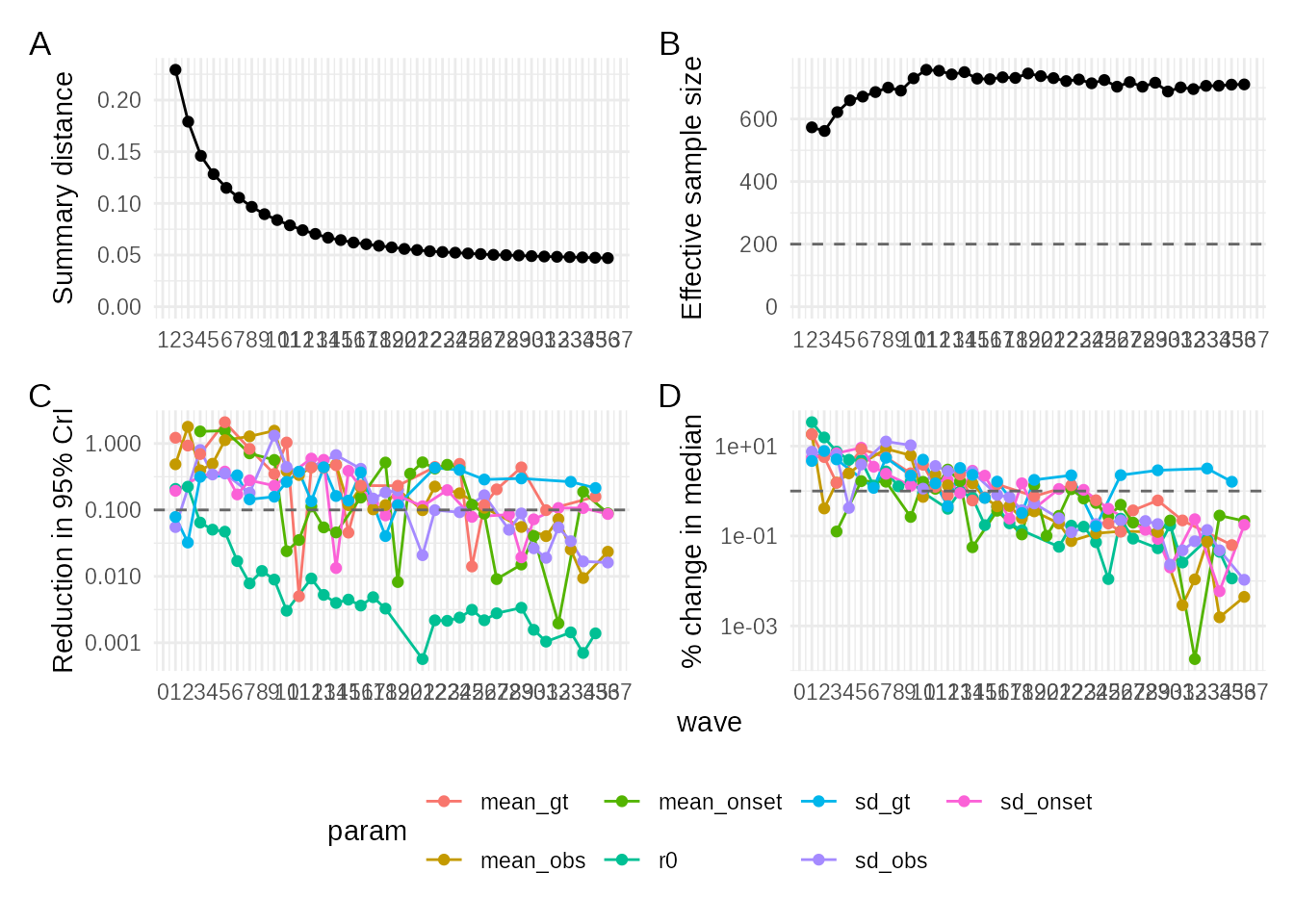
A powerful posterior predictive check. It generates new simulated datasets from the posterior and overlays their summary statistics (histograms) on the observed data. If the model is adequate and the inference successful, the simulated data should closely match the observed data.
plot_simulations(obsdata, adaptive_fit, sim_fn = sim1_fn)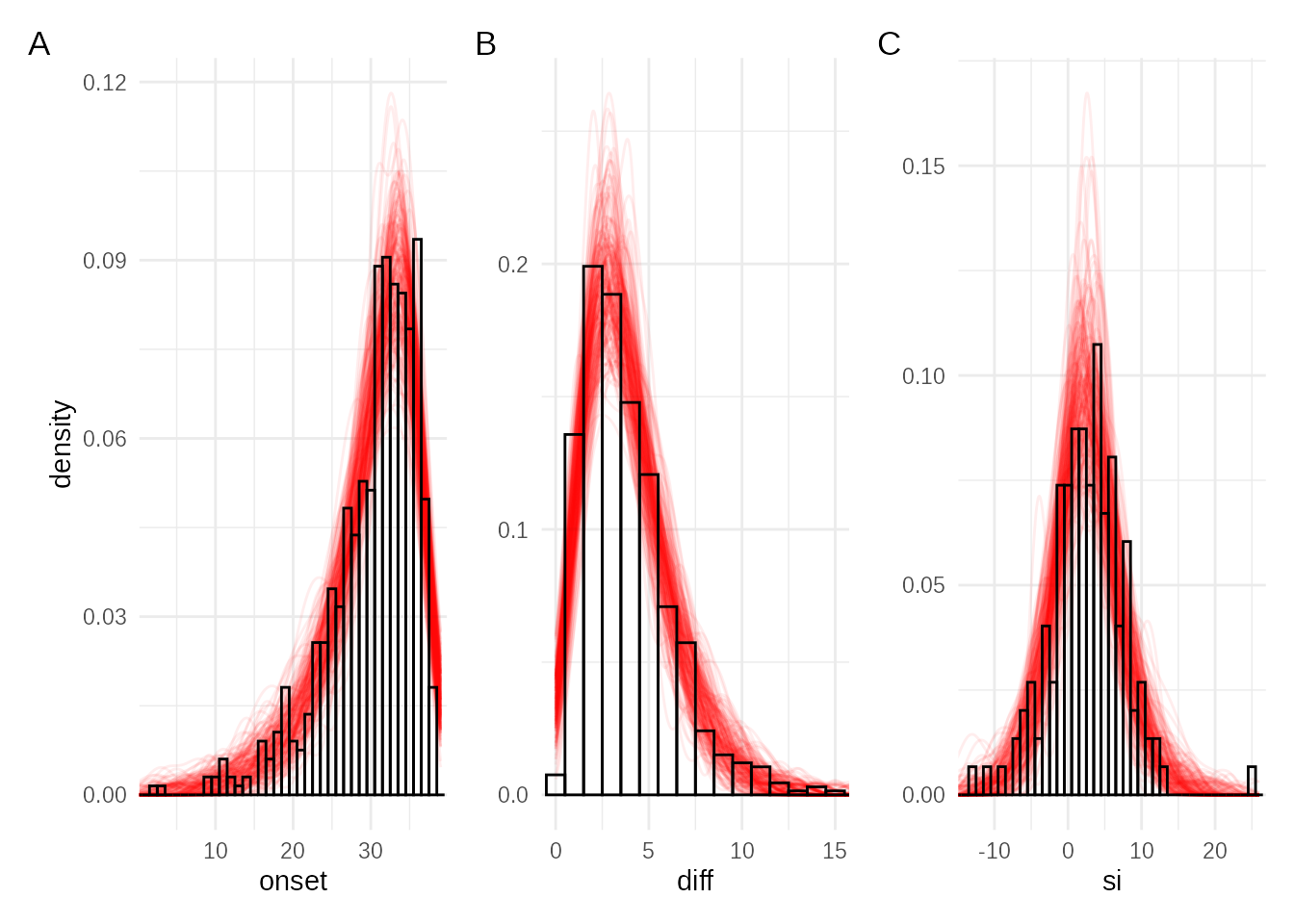
Refining the Priors
With the knowledge that the onset distribution is not informed by the
model. We imagine that we have other data to feed into this model. It is
plausible that we might have independent estimates of symptom onset
delay from traveller or household data. Likewise better estimates of the
observation delay may be available elsewhere. We replace the uniform
priors on the delay parameters with more informative log-normal
priors (lnorm2) that reflect our prior belief
about their likely scale.
Using the output of previous runs we also given more informed priors for the parameters under investigation.
priors2 = priors(
r0 ~ norm(0.18, 0.25),
mean_onset ~ lnorm2(7, 3),
sd_onset ~ lnorm2(5, 3),
mean_obs ~ lnorm2(5, 1),
sd_obs ~ lnorm2(3, 1),
# mean_gt ~ lnorm2(4, 3),
# sd_gt ~ lnorm2(3, 2),
mean_gt ~ unif(0, 12),
sd_gt ~ unif(0, 8),
R0 ~ (1+r0*sd_gt^2/mean_gt) ^ (mean_gt^2 / sd_gt^2),
~ is.finite(R0) & R0 > 0 & R0 < 12,
~ mean_onset > sd_onset,
~ mean_obs > sd_obs,
~ mean_gt > sd_gt
)
priors2## Parameters:
## * r0: norm(mean = 0.18, sd = 0.25)
## * mean_onset: lnorm2(mean = 7, sd = 3)
## * sd_onset: lnorm2(mean = 5, sd = 3)
## * mean_obs: lnorm2(mean = 5, sd = 1)
## * sd_obs: lnorm2(mean = 3, sd = 1)
## * mean_gt: unif(min = 0, max = 12)
## * sd_gt: unif(min = 0, max = 8)
## Constraints:
## * is.finite(R0) & R0 > 0 & R0 < 12
## * mean_onset > sd_onset
## * mean_obs > sd_obs
## * mean_gt > sd_gt
## Derived values:
## * R0 = (1 + r0 * sd_gt^2/mean_gt)^(mean_gt^2/sd_gt^2)We run the Adaptive ABC again with these new priors and compare the
results. This allows us to assess the robustness of our inferences to
prior specification. We also want to focus the algorithm on the elements
of the data that are unknown, by modifying the
scoreweights. We also let the algorithm converge hard as we
are relatively sure where we are investigating.
scoreweights2 = scoreweights1 *
c(sim_onset = 2, sim_diff = 0.5, sim_si = 2, sim_mad_si = 3)
adaptive_fit2 = abc_adaptive(
obsdata = obsdata,
priors_list = priors2,
sim_fn = sim1_fn,
scorer_fn = scorer1_fn,
n_sims = 4000,
acceptance_rate = 0.2,
# debug_errors = TRUE,
parallel = TRUE,
scoreweights = scoreweights2,
# widen_by = 1,
# distfit = "analytical"
)## ABC-Adaptive## Adaptive waves: ■ 0% | wave 1 ETA: 6m## Adaptive waves: ■ 1% | wave 2 ETA: 5m## Adaptive waves: ■ 2% | wave 4 ETA: 5m## Adaptive waves: ■■ 3% | wave 6 ETA: 5m## Adaptive waves: ■■ 4% | wave 9 ETA: 5m## Adaptive waves: ■■ 5% | wave 11 ETA: 5m## Adaptive waves: ■■■ 6% | wave 13 ETA: 5m## Adaptive waves: ■■■ 7% | wave 15 ETA: 5m## Adaptive waves: ■■■ 8% | wave 17 ETA: 5m## Adaptive waves: ■■■■ 9% | wave 19 ETA: 5m## Converged on wave: 21## Adaptive waves: ■■■■ 9% | wave 20 ETA: 5m
summary(adaptive_fit2)## ABC adaptive fit: 21 waves - (converged)
## Parameter estimates:
## # A tibble: 8 × 4
## # Groups: param [8]
## param mean_sd median_95_CrI ESS
## <chr> <chr> <chr> <dbl>
## 1 R0 1.930 ± 0.183 1.920 [1.650 — 2.247] 781.
## 2 mean_gt 4.283 ± 0.657 4.175 [2.420 — 7.685] 781.
## 3 mean_obs 4.884 ± 0.454 4.830 [3.829 — 6.141] 781.
## 4 mean_onset 6.570 ± 1.329 6.390 [3.746 — 10.630] 781.
## 5 r0 0.181 ± 0.011 0.181 [0.134 — 0.223] 781.
## 6 sd_gt 2.973 ± 0.981 3.086 [0.511 — 5.737] 781.
## 7 sd_obs 2.808 ± 0.522 2.794 [1.811 — 4.224] 781.
## 8 sd_onset 3.999 ± 1.053 3.967 [2.200 — 7.471] 781.
plot(adaptive_fit2,truth = sim_params, tail = 0.01)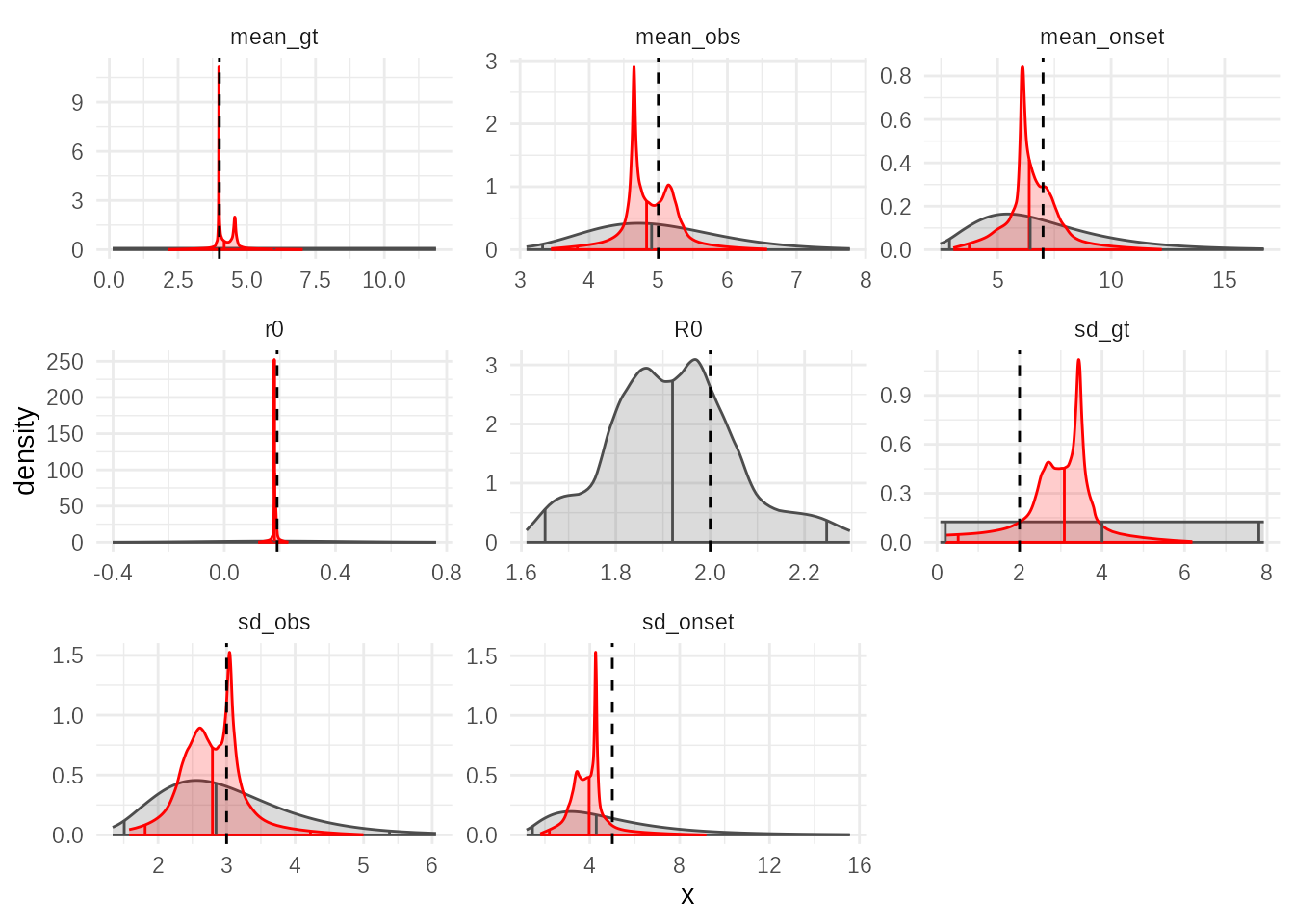
# plot_evolution(adaptive_fit2, truth = sim_params, what="proposals")And we can check that posterior resamples from the new fit are still consistent with the data. Despite the informed priors the estimate of the SD of the generation time is somewhat high, and it is not well informed by the data. This has mild knock on to the estimate of R0 which is slightly low.
plot_simulations(obsdata, adaptive_fit2, sim_fn = sim1_fn)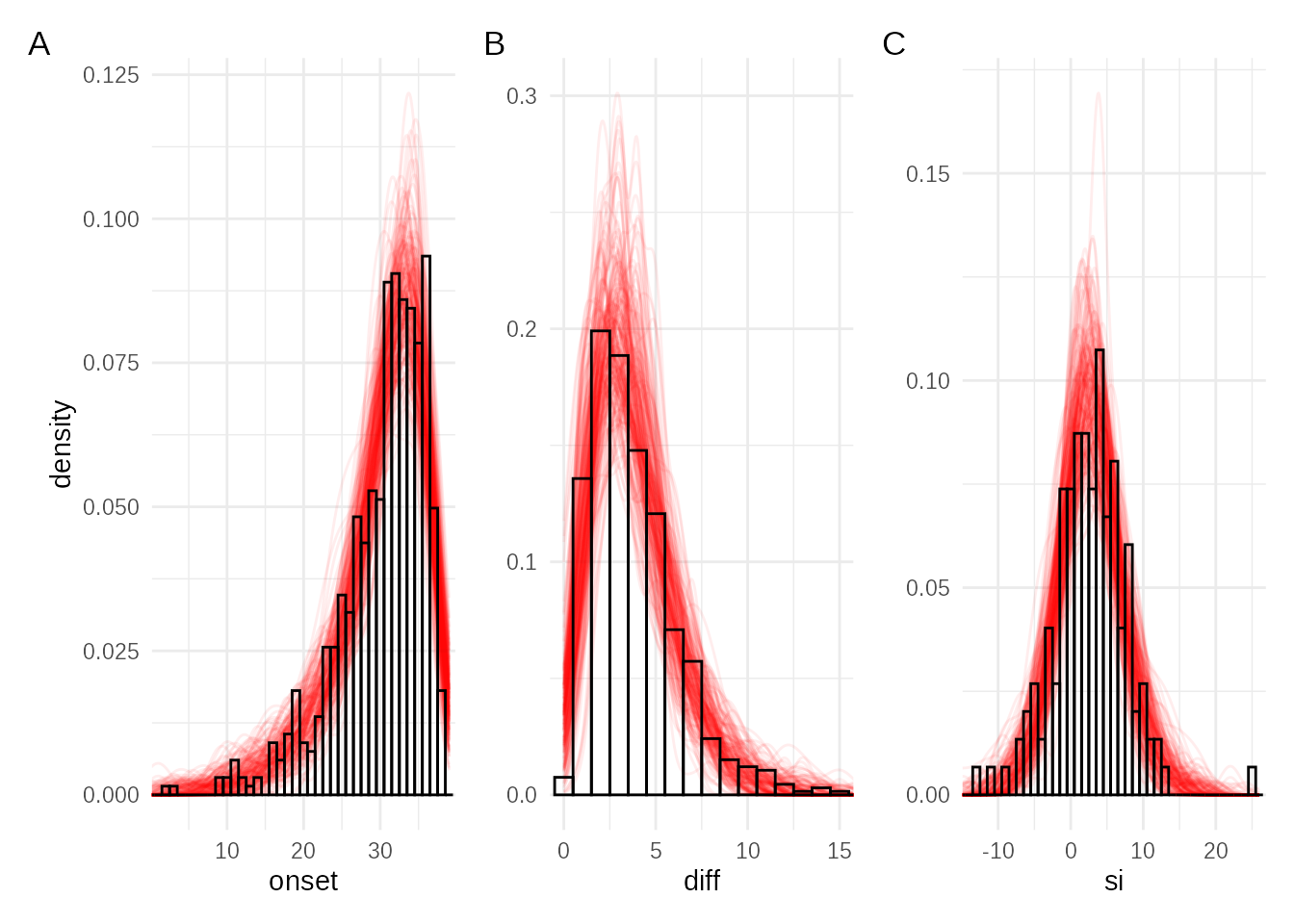
Conclusion
This vignette showcases the power of tidyabc for
tackling complex, real-world inference problems in epidemiology.
Including this tricky example where relatively short generation time is
coupled with long delay to symptom onset. By building a detailed
simulation model that captures the hidden processes of transmission and
observation, and by carefully designing the scoring function and priors,
we can use ABC to infer critical but unobservable parameters like R0 and
the generation time from limited, biased observational data. The suite
of diagnostic plots provided by tidyabc allows for thorough
evaluation of the inference quality and model adequacy.
When working with a real problem developing a simulation first and checking that the ABC machinery is able to recover the simulation parameters is a very important aspect to fitting with ABC where there are quite a lot of variables in the fitting process that all may influence the overall quality of fit.